Webinar : Contextualized Data : September 14, 2022 09:00AM Pacific Time
RegisterNo! Not all reporting tools are equal. Flow understands the complexities that arise in production. Let’s face facts: there are many reporting tools out there.
Most purport to transform your data into actionable information. Some are masquerading as configurable tools when, in reality, they need a fair degree of customization (read: scripting/coding/IT skills).
So, where does Flow fit in? Is Flow another reporting tool? You be the judge.
It’s one thing to convert data into information. It’s another thing to achieve that goal while:
Consider these one at a time.
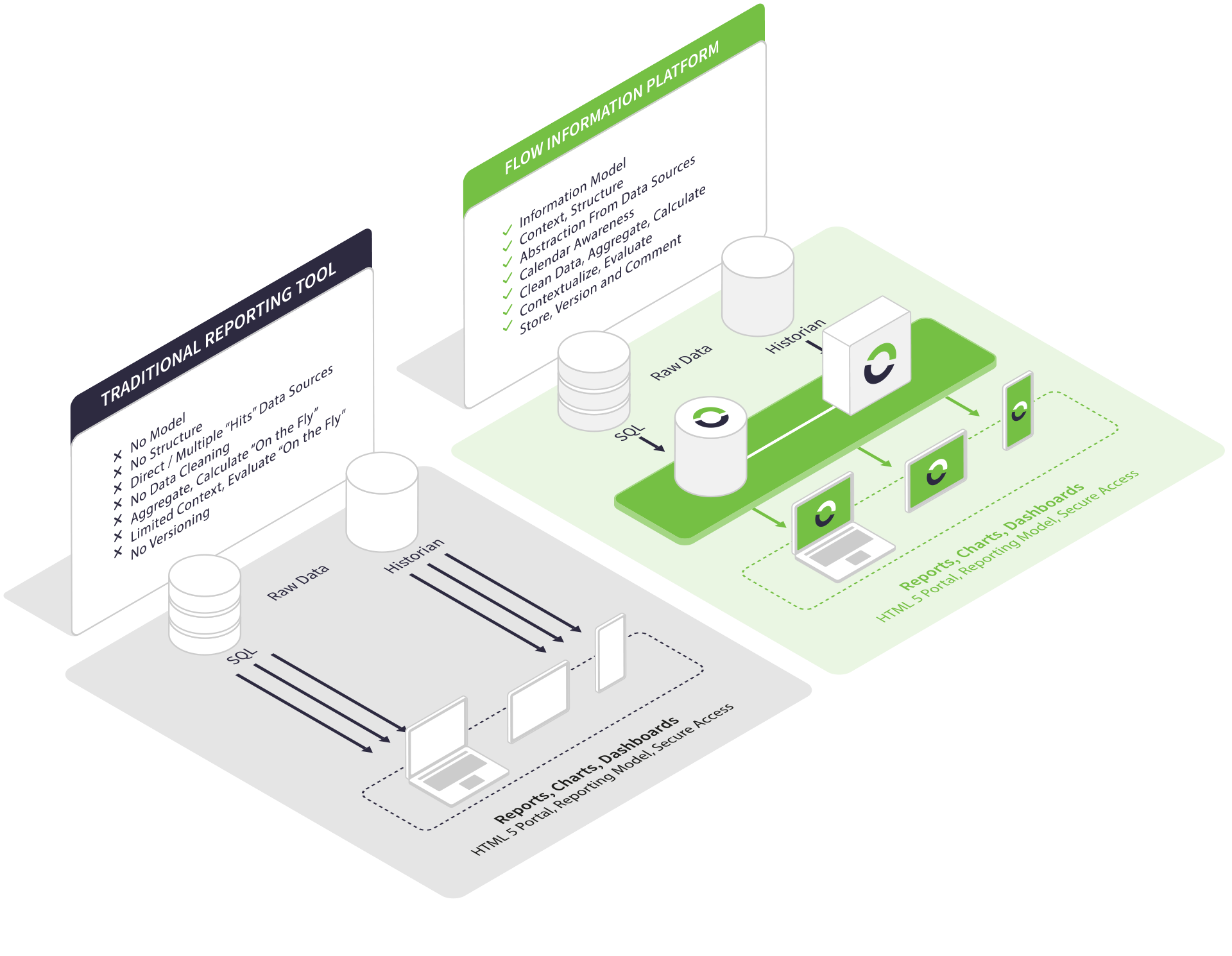
In the real world, where there are so many inputs vying for your attention, you need to ensure that you have the correct information to win the competition. How long one must wait for this accurate information is critically important.
If a tool has been designed to access data from sources at runtime (i.e., on the fly), reporting performance will likely suffer simply because of the need for retrieval. The user has to wait for the report to render. The problem compounds when you need to aggregate the raw data.
For example, you may need to add data points for 24 hours to compute a daily number. The same issue arises when evaluating KPIs based on raw data from various production units. The reporting performance is inversely proportional to the complexity of the KPI.
Granted, native reporting tools (tools that the provider of the data source built) can harness proprietary data retrieval mechanisms. But when your data resides in multiple sources, some of which are from other providers, these tools are limited.
Also, you need to clean your data before it can be ready for use in reports. Examples of this are what to do with "missing" data points, such as null values while an instrument was offline. Or how to handle spurious data points caused by noise in a signal or totalizer rollover during a reporting interval.
The above scenarios are common, but performance will degrade if your reporting tool corrects these at report rendering time.
Flow mitigates the impact on poor performance by:

It’s rare to find a facility with a single data source, or multiple data sources from the same vendor.
Best-in-breed tools focus on the genre of data/information in which those tools have the expertise, which is understandable.
For example, you will not expect the provider of an industry-leader in manufacturing of data storage tool, to also provide an industry-leading ERP tool. Possible, but not probable.
You can, and should, expect your reporting tool to collect data from your various data harvesting tools.
Viewing data from various tools in their "silos" is unacceptable. Instead, you must contextualize your information by marrying data from multiple tools. Without context, you cannot answer some of the fundamental questions an operation must answer. Questions such as:
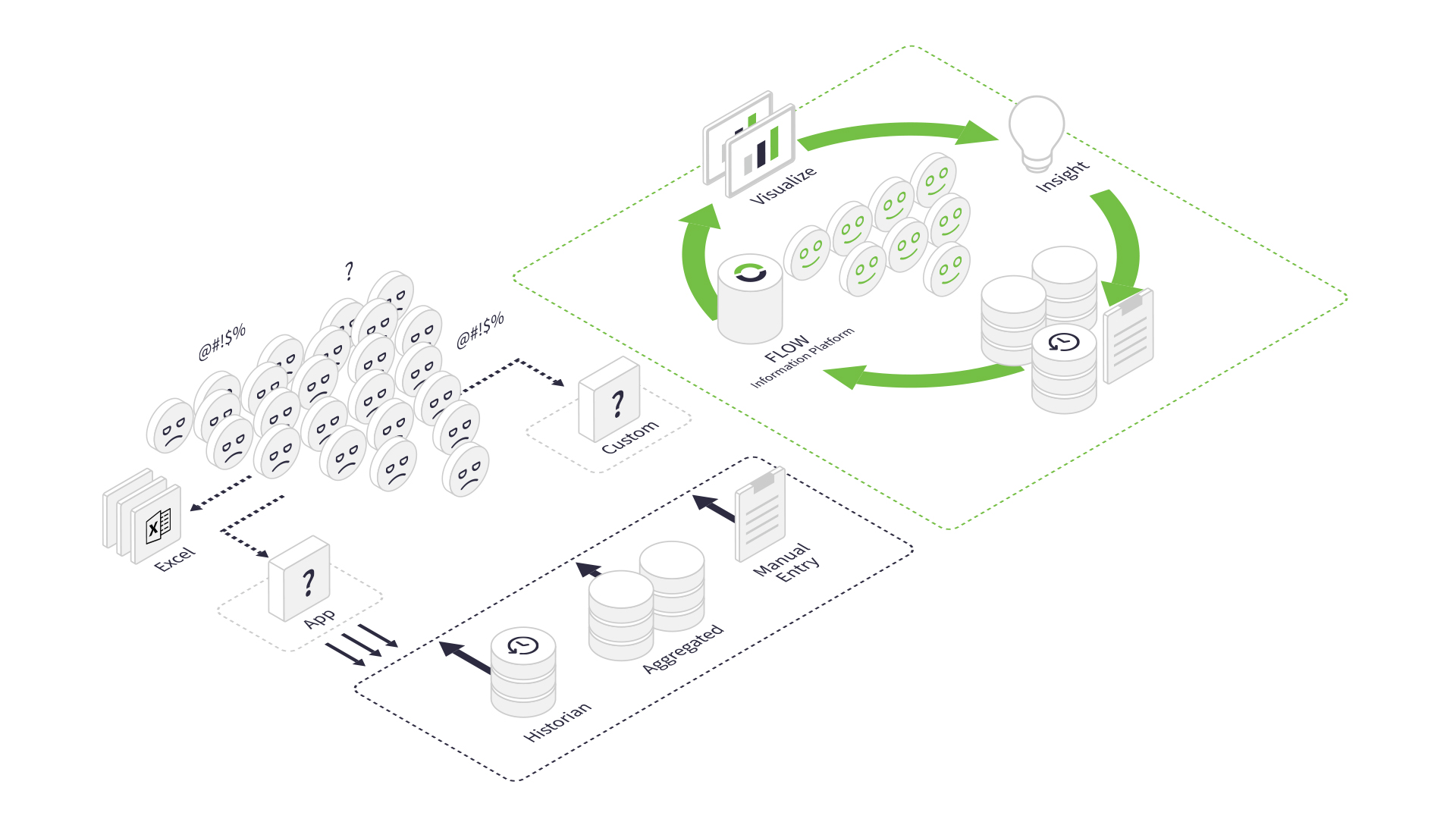
Flow can answer the above questions and more in the affirmative. In addition, by connecting to multiple data sources, Flow can provide you with context-rich information. For example, these sources may contain manufacturing, planning, finance, or human resources data.
The "human data source" is an imperative one that Flow does not ignore. Operators can capture comments against data points. These comments are then available wherever you report on those data points. These invaluable insights help to focus your improvements.
Flow provides a layer of abstraction away from your data sources and functions as a reporting platform. The report user need not understand from where the data came. Instead, they can view this information if they desire. Or, they can focus on the information they need to make decisions, confident that the underlying data has been reliably extracted and transformed.
Flow can also make this information available to your other systems. For example, do you want specific KPIs displayed on your SCADA systems? Flow can do it.
To address the challenges posed earlier, some tools sacrifice standardization and governance best practices.
The example of the ubiquitous spreadsheet tool comes to mind. With a bit of effort, one can use a spreadsheet to consolidate data from multiple sources and even include commentary. There are some caveats, though:
Besides the above governance-related issues, consider the following standardization-relation problems that present themselves:
If your reporting tool cannot achieve the above, you need to ask why! Flow can and does ensure data integrity.
What you see in a Flow report is a true reflection of the underlying data. Flow tracks and highlights this to the report user where someone has modified that data. It also shows you the updates to the data and who made them. And, if user comments are available, Flow displays that as well.
In short, Flow generates a complete audit trail to ensure that what you see is the single version of the truth
No! Not all reporting tools are equal. Lenny explains this in more detail.
Flow understands the complexities that arise in production environments and recognizes that you likely have various data sources. You need to bring that data together to give context to your information. And you need to view your information in a performant manner.
The questions posed in this blog are based on fundamental principles upon which we built Flow.
Get in touch, and we'll answer any questions you have and/or give you a no-obligation demo of what Flow can do.

Scalable information management in manufacturing requires a foundational approach to integration, robust data governance, and adoption of flexible, platform-agnostic architectures - these key points will ensure your strategy is successful.

Flow is excited to announce a new partnership with Gallarus Industry Solutions, a premier provider of Industry 4.0 solutions. This partnership aims to leverage Gallarus’s expertise in digital transformation and the Unified Namespace ecosystem and enhance Industry 4.0 adoption globally.

Flow has officially been selected by the RFK Racing Team to power their analytics for NASCAR legend Brad Keselowski in the #6 car as well as their #17 car, driven by Chris Buescher, for the 2024 NASCAR Cup Series season.